cours-2023-2024 | Documents de mes cours pour l'année 2023-2024 | FX Jollois
Relationnel et NoSQL Mongo
Connexion à Mongo local (i.e. sur le même ordinateur)
Pour se connecter à un serveur Mongo qui fonctionne sur la même machine que Python, vous devez ne rien indiquer dans la fonction MongoClient(), comme ci-dessous.
import pymongo
client = pymongo.MongoClient()
db = client.SAE
Ce code permet de se connecter à la BD SAE du serveur Mongo. Si celle-ci n’existe pas, elle ne sera pour autant pas encore créée.
Passage d’une BD relationnelle à une BD type Mongo
Dans cet exemple, nous allons utiliser la petite base de données Gymnase2000, disponible au format SQLite sur ce lien. Voici son schéma relationnel
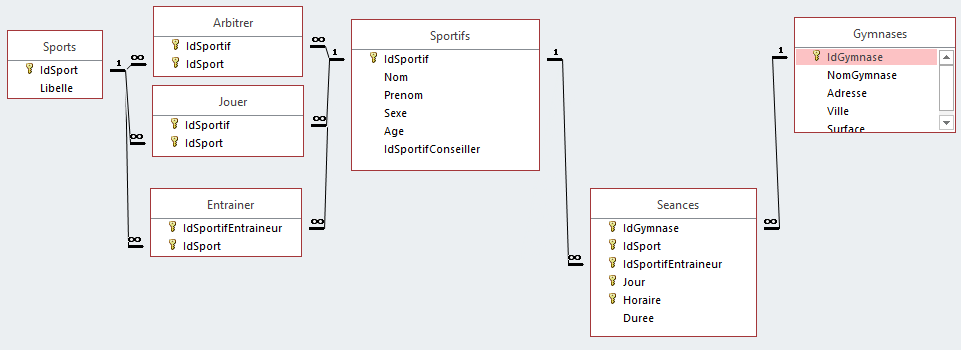
Dans ce schéma, après analyse, on peut décider de créer 2 collections :
- Sportifs : chaque document concernera un seul sportif, dans lequel on notera en plus les sports qu’il joue, qu’il entraîne et qu’il arbitre, sous la forme d’une chaîne de caractère. On devra aussi ajouter l’identifiant du sportif conseiller ;
- Gymnases : ici, chaque document concernant un seul gymnase, dans lequel on ajoutera les informations de toutes les séances prévues, dans un tableau
Création de la collection Gymnases
Connexion à la BD Gymnases
Pour se connecter à la base, on ré-utilise le code vu précédemment.
import sqlite3
import pandas
# Création de la connexion
conn = sqlite3.connect("Gymnase2000.sqlite")
Récupération des informations dans la BD
On doit tout d’abord récupérer les informations des 2 tables Gymnases et Seances, que l’on va stocker dans des DataFrames.
Attention : on va tout de suite récupérer le nom du sport en chaîne de caractères. On supprimera l’identifiant du sport ultérieurement.
gymnases = pandas.read_sql_query(
"SELECT * FROM Gymnases;",
conn
)
seances = pandas.read_sql_query(
"SELECT * FROM Seances INNER JOIN Sports USING (IdSport);",
conn
)
Intégration des séances dans le DataFrame gymnases
Maintenant, nous devons ajouter la liste des séances comme colonne du DataFrame gymnases. Pour cela, si nous considérons le gymnase avec l’identifiant 1, nous pouvons déjà récupérer l’ensemble de ces séances comme suit.
id = 1
seances.query('IdGymnase == @id')
Ensuite, pour supprimer les colonnes IdGymnase et IdSport, on peut procéder ainsi.
seances.query('IdGymnase == @id').drop(columns = [["IdGymnase", "IdSport"]])
Enfin, pour transformer le résultat (qui est un DataFrame) en un dictionnaire python, nous utilisons la fonction to_dict(), avec en paramètre orient égal à records, ceci permet de faire un tableau de dictionnaires.
seances.query('IdGymnase == @id').drop(columns = ["IdGymnase", "IdSport"]).to_dict(orient = "records")
Ce code peut maintenant s’intégrer dans une list comprehension pour créer une liste de dictionnaires pour chaque gymnase.
liste = [seances.query('IdGymnase == @id').drop(columns=["IdGymnase", "IdSport"]).to_dict(orient = "records") for id in gymnases.IdGymnase]
liste
On peut maintenant ajouter ceci au DataFrame gymnases, comme ci-dessous.
gymnases = gymnases.assign(Seances = liste)
gymnases.head()
Intégration du DataFrame gymnases à Mongo
Grâce à la même fonction to_dict() et la fonction insert_many() sur une collection, nous allons pouvoir intégrer les données à Mongo. Le code suivant va donc créer la BD SAE (car vide pour le moment), puis la collection Gymnases, et ensuite y placer toutes les données.
db.Gymnases.insert_many(gymnases.to_dict(orient = "records"))
Vous pouvez aller voir le résultat dans Compass. Vous pouvez aussi tester directement en interrogeant Mongo pour le nombre de documents de la collection :
db.Gymnases.count_documents({})
Et aussi sur le contenu de la collection :
list(db.Gymnases.find())
Suppression d’une collection
Si jamais vous aviez fait une erreur, vous pouvez supprimer une collection (voire un BD) soit directement dans Compass, soit en passant par python. Le code ci-dessous permet de supprimer la collection Gymnases par exemple.
db.Gymnases.drop()
Création de la collection Sportifs
A FAIRE
Jointure entre deux collections
Supposons que vous avez créer la collection Sportifs, avec comme champs IdSportif. Si nous souhaitons récupérer les informations l’entraineur pour chaque séance, pour chaque gymnase, nous pouvons exécuter le code suivant :
pandas.DataFrame(list(db.Gymnases.aggregate([
{ "$limit": 1 },
{ "$unwind": "$Seances" },
{ "$lookup": {
"from": "Sportifs",
"localField": "Seances.IdSportifEntraineur",
"foreignField": "IdSportif",
"as": "Entraineur"
}}
])))
A noter : le résultat d’un lookup est forcément un tableau, même s’il n’y a qu’une seule valeur. A vous de faire le travail pour l’extraire dans un littéral simple si vous le souhaitez (par exemple avec $first).
A FAIRE : récupérer les informations du conseiller pour chaque sportif.
Passage d’une BD type Mongo à une BD relationnelle
Importation des données dans Mongo
Dans Compass, vous allez charger les données présentes dans le fichier movies.json. Pour cela, dans le logiciel, suivez les étapes suivantes :
- Cliquer sur le + à droite du nom de la BD
SAE - Ecrire le nom de la nouvelle collection (
moviespar exemple) - Cliquer sur Create Collection
- Cliquer ensuite sur ADD DATA et Import File
- Sélectionner le fichier que vous venez de télécharger
- Cliquer sur Import
Les données sont maintenant dans Mongo. On peut voir le contenu du premier document comme suit.
db.movies.find_one()
Création de la BD SQLite
movies = sqlite3.connect("Movies.sqlite")
On va commencer par créer une table faisant la correspondance entre l’identifiant spécifique à Mongo (et peu facile à gérer par ailleurs) et un identifiant créé automatiquement.
corresp = pandas.DataFrame(list(db.movies.find({}, { "_id": 1 })))
corresp = corresp.assign(idFilm = range(1, len(corresp) + 1))
corresp
Gestion des informations sur le genre
Nous voyons par exemple qu’il y a le champs genres contenant une liste de genres pour un film. La bonne façon de faire pour passer en relationnel serait de :
- Créer une table
genrescontenant deux colonnes :idGenre(à créer) etlibGenre - Créer une table
film_genrecontenant deux colonnes :idFilm(à créer aussi éventuellement) etidGenre
On peut donc avoir la liste des genres avec la commande suivante.
db.movies.distinct("genres")
Avec un peu de manipulation python, on peut créer la table genres comme ci-dessous.
liste_genres = db.movies.distinct("genres")
genres = pandas.DataFrame({
"id_genre": range(1, len(liste_genres)+1),
"genre": liste_genres
})
genres
On peut donc déjà l’intégrer à la BD SQLite
genres.to_sql('genres', movies, index = False)
Pour créer la deuxième table, nous devons déjà récupérer la liste des genres pour chaque film. Ensuite, on enlève les données manquantes (i.e. des films sans genres). Et on récupère les nouveaux identifiants de films créés avant. On supprime au final la colonne _id.
df_genres = pandas.DataFrame(list(db.movies.find({}, { "genres": 1 }))) \
.dropna() \
.merge(corresp) \
.drop(columns = ["_id"])
df_genres
On doit maintenant décomposer la colonne genres pour avoir un genre par ligne. En ajustant le code vu précédemment en cours, on arrive à ceci.
film_genres = pandas.concat([pandas.DataFrame(g).assign(idFilm = i) for (i, g) in zip(df_genres.idFilm, df_genres.genres) if g])
film_genres.columns = ["genre", "idFilm"]
film_genres
Au final, en réalisant une jointure avec le DataFrame précédent, on arrive à créer la table voulue.
film_genre = pandas.merge(film_genres, genres).drop(columns = "genre").sort_values(by = "idFilm")
film_genre
On l’intègre elle aussi dans la BD SQLite.
film_genre.to_sql('film_genre', movies, index = False)
Vous pouvez ouvrir votre base de données avec DBeaver (par exemple) pour voir le contenu de celle-ci. Il devrait s’y trouver les 2 tables précédemment exportées.
A FAIRE
- Gérer le casting (acteurs, champs
cast) de la même façon que les genres, ainsi que les pays (champscountries), les directeurs (directors), les scénaristes (writers) et les langues (languages) ; - Créer une table
ratingintégrant les valeurs du champsrated; - Faire de même pour le champs
type; - Le champs
awardsdoit devenir 3 colonnes de la tableFilmà produire au final (wins,nominationsettext) ; - On va créer une table
imdbintégrant les informations du champsimdbet donc l’identifiant du film concerné ; - On va faire de même pour le champs
tomatoes.